Track 3 Overview
Deepfake realism has spurred numerous detection competitions, but most emphasize image-level classification, overlooking spatial localization and interpretable trace analysis. The localization of manipulated regions improves the explainability of decisions, and the increasing number of multimodal forgeries increases the risk.
We introduce the Deepfake Detection, Localization, and Explainability Challenge, supported by a large-scale multimodal deepfake description dataset (100K+ samples) that leverages Qwen3-VL to enrich the DDL-I corpus and advances spatial localization and explainability.
Dev Phase
In this phase, we provide a batch of image data for participants to familiarize themselves with the submission format. Participants can see their scores by submitting the results and adjust their training methods accordingly. Data download path:
https://modelscope.cn/datasets/DDLteam/DDL_X/files.
TimeLine: 4.22 - 5.14
Test Phase
Phase 1: We will release a new test set covering forgery detection, localization, and explainable tasks. Participants will perform inference on the test set based on the model trained in Train Phase, upload results according to the specified format, and the platform will automatically start the evaluation and generate scores.
TimeLine: 5.15 - 5.31
Phase 2: We selected the top ten teams from the Codebench leaderboard to advance to the semi-finals, and used the best result submitted by each team for a Rubric score. (The scoring rules will be announced later.) We combined the Rubric scores with the Codabench leaderboard scores to determine the final ranking.
TimeLine: 6.1 - 6.8
Competition website: https://www.codabench.org/competitions/15686/
Step 1: Register for the Challenge
Don't miss your chance to participate in this exciting competition! Showcase your deepfake detection skills and compete against others.
After registering, please follow the next step to complete your registration on Codabench.
Step 2: Register on Codabench Platform
🔥🔥 The challenge will be hosted on the Codabench platform. Participants will register on this platform, which will provide training and testing data, evaluation scripts, and performance leaderboards.
Evaluation Metrics
- Detection: The metrics for this task is the ACC score.
- Localization: The metrics for this task is the IoU score.
- Explainability: The metrics for this task is the BERTScore [1] and Rubrics score (for Test phase2, released later).

The Codebench leaderboard score calculation formula is as follows:
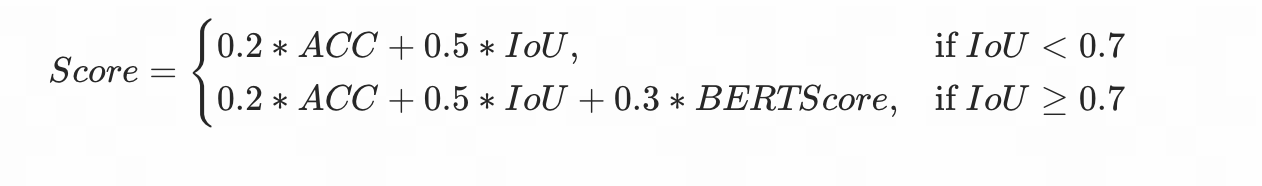
The score of phase2 can be calculated by following:

The 8 Rubrics Criteria
Standard 1: Accurate Foundational Facts and Subject Attributes (Weight: 10)
Requirement: Basic subject attributes mentioned in the explanation, such as gender, age group, skin tone, hair, facial hair, glasses, and obvious occlusions, must strictly match the image. The explanation must not misidentify visible subject attributes.
Scoring:
- Fully Satisfied (2): Attributes mentioned are all correct and consistent with the image.
- Partially Satisfied (1): No attributes are mentioned, or attributes are mentioned but only partially correct with minor inaccuracies that do not affect the overall judgment.
- Not Satisfied (0): Attributes are clearly wrong (e.g., misidentifying gender, presence/absence of glasses).
Examples:
- Fully Satisfied: "The elderly man wearing glasses shows texture discontinuity along the right cheek near the glasses frame."
- Not Satisfied: "The middle-aged woman without glasses shows distortion near the cheek," when the image actually shows an elderly man wearing glasses.
Standard 2: Visual Grounding in Observable Evidence (Weight: 12)
Requirement: The explanation must be grounded in visual evidence that is directly observable in the image. It must not speculate about unseen generation models, editing pipelines, or post–processing methods.
Scoring:
- Fully Satisfied (2): All claims are grounded in directly observable visual features.
- Partially Satisfied (1): Mostly grounded but contains minor speculative elements, or provides only generic visual descriptions without specific detail.
- Not Satisfied (0): Relies primarily on speculation about generation methods or tools without observable evidence from the image.
Examples:
- Fully Satisfied: "There is a visible color discontinuity along the left jawline, where the cheek boundary does not blend smoothly with the neck."
- Not Satisfied: "The image was generated by StyleGAN and then refined with Poisson blending," without any evidence from the image.
Standard 3: Precise Localization of Anomalous Facial Regions (Weight: 15)
Requirement:
- For fake/manipulated images: The explanation should clearly identify where the anomaly appears on the face, such as the eyes, mouth corners, nose bridge, cheeks, jawline, hairline, ears, or face boundary. Generic statements like "the face looks fake" are insufficient.
- For real/bonafide images: The explanation should reference specific facial regions when describing natural consistency (e.g., "the skin texture transitions smoothly from forehead to cheeks"). Simply stating "the face looks real" without referencing any specific region is insufficient.
Scoring:
- Fully Satisfied (2): Clearly identifies specific facial regions with precise descriptions.
- Partially Satisfied (1): Mentions facial regions but lacks precision, or uses somewhat generic language with partial localization.
- Not Satisfied (0): Only provides whole–face generic statements without any regional specificity.
Examples (Fake):
- Fully Satisfied: "The artifact is concentrated around the subject's right mouth corner, where the lip edge becomes blurred and misaligned with the cheek texture."
- Not Satisfied: "The whole face looks strange and unnatural."
Examples (Real):
- Fully Satisfied: "The skin texture transitions naturally from the nose bridge to both cheeks, with consistent pore density and no boundary artifacts along the jawline."
- Not Satisfied: "The face looks normal and real."
Standard 4: Comprehensive Facial Artifact and Consistency Analysis (Weight: 15)
Requirement:
- For fake/manipulated images: The explanation should identify both low-level visual artifacts and higher–level facial inconsistencies. Low–level includes: pixel discontinuity, blurred boundaries, inconsistent texture, abnormal noise, color blocks, lighting breaks, resolution mismatch. Higher–level includes: asymmetric facial structure, misaligned facial components, unnatural shadows, inconsistent gaze direction, or mismatched eye–mouth expressions.
- For real/bonafide images: The explanation should describe natural consistency across multiple dimensions, such as texture continuity, lighting coherence, geometric regularity, expression coordination, or boundary smoothness. Mentioning at least two dimensions of natural consistency is expected.
Scoring:
- Fully Satisfied (2): Covers at least two distinct dimensions of analysis (low–level + high–level for fake; multiple consistency dimensions for real).
- Partially Satisfied (1): Covers only one dimension, or mentions multiple dimensions but with insufficient detail.
- Not Satisfied (0): Provides no substantive analysis, or only gives a subjective impression without any specific visual evidence.
Examples (Fake):
- Fully Satisfied: "The left cheek contains block–like color patches and lower–resolution texture, while the mouth is raised in a smile but the eye region lacks corresponding muscle contraction, making the expression physically inconsistent."
- Not Satisfied: "The person looks fake because the image has a weird feeling."
Examples (Real):
- Fully Satisfied: "The facial skin shows consistent micro–texture across all regions, and the lighting creates natural shadow gradients from the nose bridge that align with the illumination direction visible on both cheeks."
- Not Satisfied: "Everything looks fine, it's real."
Standard 5: Label-Correct and Prediction-Faithful Explanation (Weight: 20)
Requirement: The predicted label must match the ground-truth label, and the explanation must be faithful to the predicted label.
- If the ground truth is fake/manipulated/attack, the prediction should also be fake/manipulated/attack, and the explanation must provide observable facial evidence supporting that fake prediction.
- If the ground truth is real/bonafide, the prediction should also be real/bonafide, and the explanation must describe the natural consistency of the face or the absence of visible manipulation artifacts.
- If the predicted label does not match the ground-truth label, this criterion scores 0 regardless of explanation quality.
- If the explanation contradicts the predicted label, this criterion also scores 0.
Scoring:
- Fully Satisfied (2): Prediction matches ground truth AND explanation is fully faithful to the prediction with supporting evidence.
- Partially Satisfied (1): Prediction matches ground truth, but explanation is weak, generic, or only partially supports the prediction.
- Not Satisfied (0): Prediction does not match ground truth, OR explanation contradicts the prediction.
Examples:
- Fully Satisfied: Ground truth: Fake. Predicted: Fake. "The image is predicted as fake because the right jawline shows a sharp color discontinuity, and the skin texture around the mouth is inconsistent with the surrounding facial regions."
- Not Satisfied: Ground truth: Real. Predicted: Fake. "The image is predicted as fake because there are artifacts around the cheek and jawline."
- Not Satisfied: Ground truth: Fake. Predicted: Fake. "The face appears natural, with consistent lighting, smooth facial boundaries, and no visible manipulation artifacts."
Standard 6: Alignment Between Textual Explanation and Predicted Bounding Box (Weight: 12)
Requirement:
- For fake/manipulated images: The facial region described in the textual explanation must have high spatial overlap with the predicted bounding box. Explanations that describe one facial region while the bbox highlights a different or unrelated region should be penalized.
- For real/bonafide images: The model should either output no localization bbox (indicating no manipulated region), or output a bbox covering the full face with an explanation that no localized anomaly was found. Outputting a small–region bbox pointing to a specific area while claiming the image is real is contradictory.
Scoring:
- Fully Satisfied (2): Strong spatial alignment between text description and bbox (fake), or appropriate bbox behavior for real images.
- Partially Satisfied (1): Partial overlap — the text and bbox reference the same general area but with noticeable offset, or bbox is slightly larger/smaller than the described region.
- Not Satisfied (0): Clear mismatch — text describes one region, bbox covers a completely different area; or for real images, a localized bbox contradicts the real prediction.
Examples (Fake):
- Fully Satisfied: The explanation states "There is a clear texture discontinuity around the left mouth corner," and the predicted bbox tightly covers the left mouth corner region.
- Not Satisfied: The explanation states "The anomaly appears around the left eye," but the predicted bbox is placed on the lower jaw or background area.
Examples (Real):
- Fully Satisfied: Predicted as real, no bbox output or full–face bbox with explanation "No localized manipulation region detected."
- Not Satisfied: Predicted as real, but a small bbox is placed on the right cheek without justification.
Standard 7: Face-Centered Explanation Without Environmental Hallucination (Weight: 8)
Requirement: The explanation must focus on the face and directly relevant facial regions. It should not rely on irrelevant clothing, background, or scene descriptions, and it must not hallucinate environmental objects or background defects that are not present.
Scoring:
- Fully Satisfied (2): Explanation focuses entirely on facial features and directly relevant regions.
- Partially Satisfied (1): Mostly face-centered but contains minor irrelevant references to non-facial elements that do not dominate the explanation.
- Not Satisfied (0): Relies primarily on background, clothing, or scene descriptions, or hallucinates environmental elements not present in the image.
Examples:
- Fully Satisfied: "The skin tone on both cheekbones is uneven, with grid-like artifacts visible on the left cheek."
- Not Satisfied: "The face is fake because the window frame in the background is bent and the clothing texture on the shoulders is misaligned."
Standard 8: Clear, Definite, and Non–Ambiguous Language (Weight: 8)
Requirement: The explanation should use clear and decisive visual descriptions. It should avoid vague terms such as "possibly," "probably," "may be," or "seems" when describing concrete visual evidence. It may describe the degree of fakeness, but the visual evidence itself must be stated definitively.
Scoring:
- Fully Satisfied (2): All visual evidence is stated definitively with clear, specific language.
- Partially Satisfied (1): Mostly clear but contains occasional hedging language or vague references.
- Not Satisfied (0): Dominated by vague, uncertain, or ambiguous language throughout.
Examples:
- Fully Satisfied: "There are obvious color blocks around the right cheek, and the face boundary near the jawline is discontinuous."
- Not Satisfied: "There may possibly be some strange artifacts somewhere on the face."
Submission Format
- The model output should be a single confidence number of the input image being fake and the corresponding predicted manipulated mask. The expected submission format is like below:
The submitted folder format is like below:
json (folder)

The format of the JSON file can be referenced as follows:
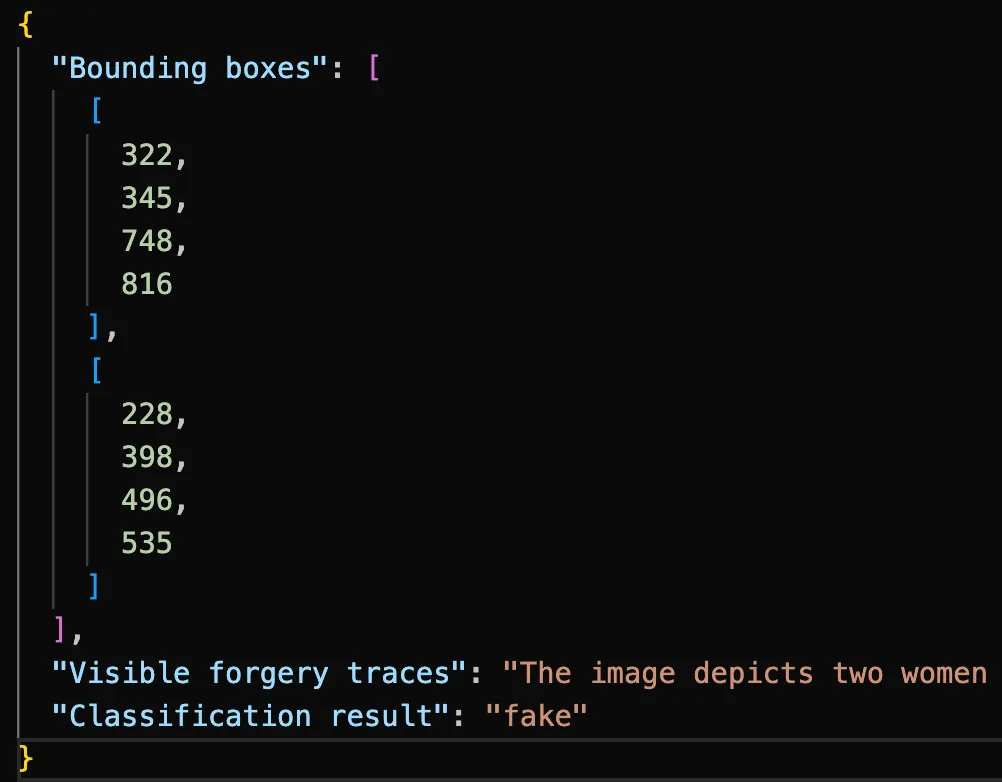
Required fields:
- Bounding boxes: [xx, xx, xx, xx] (None for real images)
- Visible forgery traces: xxx.
- Classification result: fake (real for real images)
It is important to note that the detection task calculates the ACC metric for all images, the localization task calculates the IoU metric only for images where the ground truth is fake, and the interpretation text calculates BERTScore for all images.
Please also note that the bounding box coordinates given in the interpretability text are mapped to the [1-1000] range, following the standard adopted by most current MLLM.
Assume the original image has a width of W, a height of H, and original coordinates of (x₁, y₁, x₂, y₂), the mapped coordinates are calculated as follows:
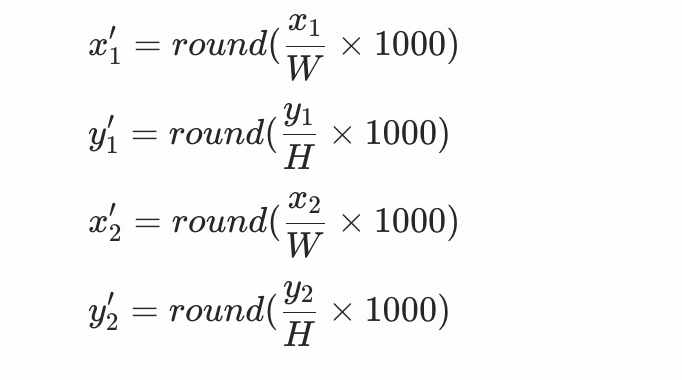
Datasets
Our dataset has been open-sourced, related information about the dataset can be found on [2, 3].
Participants can use the image portions to train their models.
References
- [1] BERTScore: Evaluating Text Generation with BERT (https://arxiv.org/abs/1904.09675)
- [2] DDL: A Large-Scale Datasets for Deepfake Detection and Localization in Diversified Real-World Scenarios (https://arxiv.org/abs/2506.23292)
- [3] https://github.com/inclusionConf/DDL/blob/main/README.md
Competition Rules
1. Model Submission Requirements
Each track permits only one model submission to address the designated tasks.
All pre-trained backbone models used must be open-source. Teams that develop proprietary backbone models during the competition are required to publicly release their model specifications and training protocols under an open-source license (e.g., MIT, Apache 2.0) during the competition period.
Winning solutions must open-source their complete implementation, including:
- Training pipelines and hyperparameter configurations
- Evaluation code and reproducibility documentation
- Final model weights in standard formats
2. Dataset Usage Requirements
Only organizer-recommended, publicly released datasets are permitted for training and evaluation.
Participants may use extended samples generated from these recommended datasets via data augmentation or deepfake tools for training, but all generation tools used must be submitted to the organizers to ensure reproducibility.
The use of any additional external datasets is strictly prohibited.
3. Violations and Sanctions
Violations of the above rules will result in disqualification. The organizing committee reserves the final authority over all competition-related matters.